Warum GA4 intern unterschiedliche Zahlen zeigt – und warum das oft korrekt ist
Dieselbe Property. Dieselben Ereignisse. Und trotzdem andere Zahlen je nach Report, Tab oder Exploration. Das wirkt wie ein Datenfehler, ist innerhalb von GA4 aber oft die Folge unterschiedlicher Berichtskontexte.
Wenn dieselbe Frage in GA4 mehrere Antworten bekommt
Das eigentliche Problem ist oft nicht ein falscher Wert – sondern die Annahme, dass alle Reports dieselbe Realität zeigen müssten.
In der Praxis fällt Data Mismatch in GA4 meist nicht auf, weil eine Zahl komplett absurd wäre. Er fällt auf, weil zwei plausible Zahlen nebeneinanderstehen und nicht zusammenpassen. Traffic Acquisition zeigt andere Werte als ein Explore Report. Users wirken niedriger oder höher als erwartet. Key Events verändern ihre Größenordnung je nach Kontext.
Genau an diesem Punkt beginnt die typische Fehlinterpretation. Unterschiedliche Zahlen aus derselben Property werden wie widersprüchliche Daten gelesen. Tatsächlich werden hier aber oft unterschiedliche Aggregationslogiken, Identitätsmodelle und Berichtskontexte miteinander verwechselt.
Schon der Berichts-Snapshot zeigt genau dieses Grundproblem. Auf einer Oberfläche stehen aktive Nutzer, neue Nutzer, Ereignisanzahl, Seiten, Quellen und Sitzungen nebeneinander. Das wirkt wie ein einheitlicher Zahlenraum. In Wirklichkeit werden dort bereits unterschiedliche Ebenen parallel gezeigt.
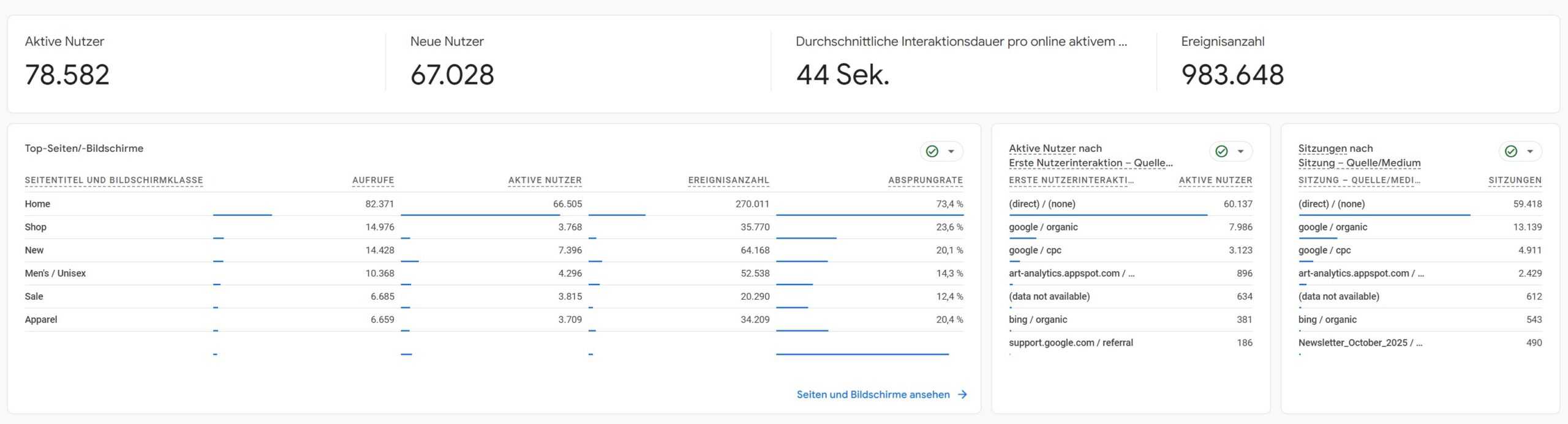
Der Berichts-Snapshot wirkt wie eine neutrale Übersicht. Tatsächlich stehen hier bereits Nutzer-, Sitzungs- und Eventlogiken nebeneinander.
Genau deshalb beginnt der Mismatch oft nicht erst beim Vergleich zweier Spezialreports. Er beginnt schon dort, wo unterschiedlich gebaute Kennzahlen auf derselben Oberfläche als direkte Vergleichswerte wahrgenommen werden.
Nicht jede Abweichung in GA4 ist ein Datenproblem. Viele Abweichungen entstehen, weil dieselbe Property aus unterschiedlichen internen Perspektiven gelesen wird.
Die naheliegende Lesart: Tracking ist kaputt
Wenn Zahlen nicht übereinstimmen, wirkt die einfachste Erklärung sofort plausibel: Das Tracking muss fehlerhaft sein. Events feuern doppelt. Sessions werden falsch gezählt. Conversions stimmen nicht. Oder GA4 macht schlicht etwas Unsauberes.
Diese Lesart ist deshalb so attraktiv, weil sie schnell Ordnung schafft. Ein scheinbarer Widerspruch wird auf eine einzige Ursache reduziert. Das Problem daran: Sie unterstellt, dass alle Reports dieselben Objekte, dieselben Zählweisen und dieselben Zuordnungsregeln verwenden. Genau das ist in GA4 aber nicht der Fall.
Wenn zwei Reports unterschiedliche Zahlen zeigen, muss einer davon falsch sein.
GA4 ist kein einheitlicher Zahlenraum
GA4 sieht auf der Oberfläche wie ein einziges Reporting-System aus. Intern arbeitet es aber mit verschiedenen Ebenen von Realität. Manche Reports denken stärker auf User-Ebene. Andere auf Session-Ebene. Wieder andere auf Event-Ebene oder auf einer Attributionslogik, die Ereignisse nachgelagert anders zuordnet.
Dadurch entstehen keine beliebigen Unterschiede, sondern systematische Verschiebungen. Wer diese Verschiebungen ignoriert, vergleicht nicht zwei Werte desselben Objekts, sondern zwei unterschiedlich verdichtete Datenräume.
- Users, Active Users und Total Users sind keine austauschbaren Varianten derselben Zahl.
- Sessions und Engaged Sessions beschreiben nicht dieselbe Einheit mit anderem Label, sondern unterschiedliche Qualitätslogiken.
- Standard Reports und Explorations arbeiten nicht im identischen Berichtskontext.
- Attribution Settings, Report Identity, Date Range und Lookback Windows verändern, wie Ereignisse zugeordnet und gezählt werden.
- Cardinality, Thresholding und sampling-nahe Berichtseffekte können Werte zusätzlich verdichten oder verschieben.
Besonders sichtbar wird das in der Gegenüberstellung von Nutzergewinnung und Traffic Acquisition. Beide Reports sprechen scheinbar über Kanäle. Aber sie sprechen nicht über dasselbe Objekt.
Im Bericht zur Nutzergewinnung wird die Akquisition auf Basis der ersten Nutzerinteraktion gelesen. Dadurch steht dort die Frage im Vordergrund, über welchen Kanal ein Nutzer ursprünglich ins System gekommen ist. Traffic Acquisition liest dagegen die Sitzung. Dort geht es nicht um den ersten Kontakt, sondern um die aktuelle Interaktionseinheit.
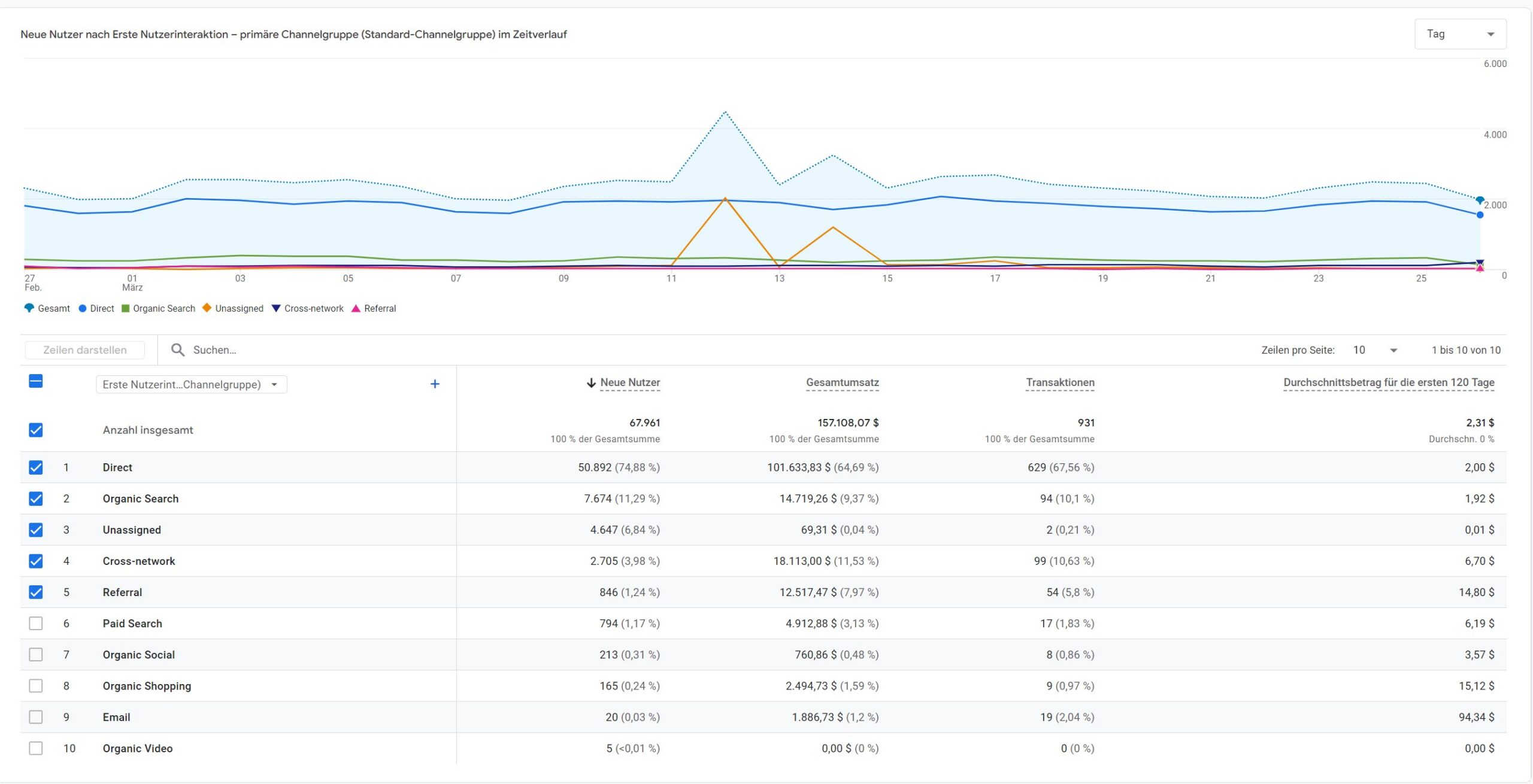
Nutzergewinnung arbeitet auf First-User-Logik. Die Kanalwerte zeigen, wo Nutzer ursprünglich gewonnen wurden – nicht, wie aktuelle Sitzungen verteilt sind.
Im Screenshot zur Nutzergewinnung ist genau das erkennbar. Die Tabelle ist auf neue Nutzer und erste Nutzerinteraktion aufgebaut. Direct wirkt hier dominant, weil viele Nutzer in dieser Property ihren ersten messbaren Einstieg unter Direct erhalten haben. Diese Logik beantwortet eine Akquisitionsfrage auf User-Ebene.
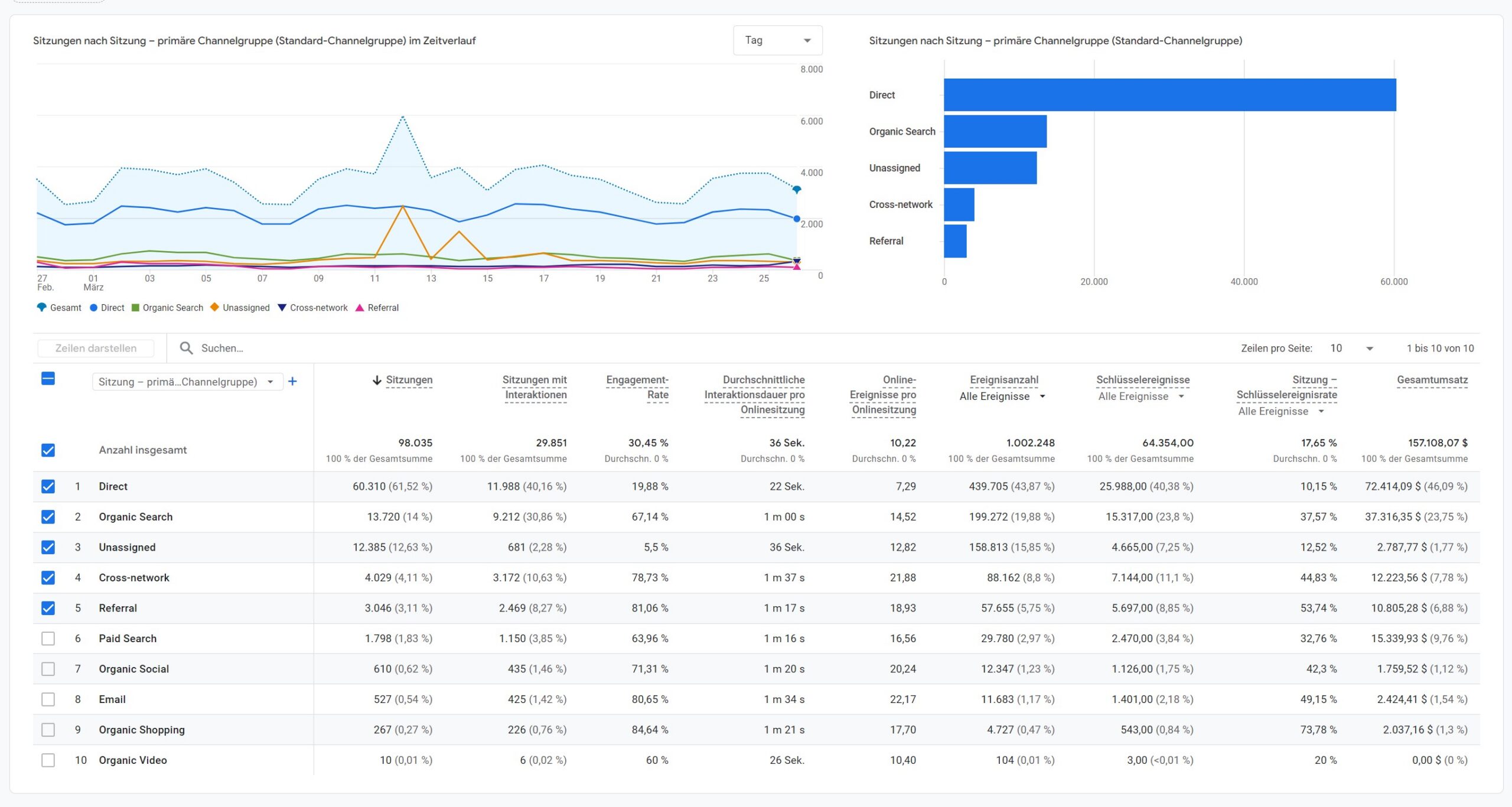
Traffic Acquisition arbeitet auf Sitzungslogik. Hier wird nicht der erste Nutzerkontakt bewertet, sondern die Verteilung aktueller Sitzungen und ihrer Qualität.
Im Traffic-Acquisition-Screenshot verschiebt sich das Bild. Direct ist weiterhin groß, aber nun auf Sitzungsbasis. Gleichzeitig treten Metriken wie Sitzungen, Sitzungen mit Interaktionen, Engagement-Rate oder Schlüsselereignisse in den Vordergrund. Genau deshalb dürfen die Zahlen nicht eins zu eins gegen die Werte aus der Nutzergewinnung gehalten werden.
Wenn sich Direct, Organic Search oder Referral zwischen diesen beiden Screenshots unterschiedlich verhalten, ist das nicht automatisch ein Fehler. Es ist die Folge davon, dass derselbe Kanal einmal als erster Nutzerkontakt und einmal als Sitzung gelesen wird.
Wo Zahlen innerhalb von GA4 auseinanderlaufen
Der wichtigste Schritt in der Diagnose besteht nicht darin, sofort nach einem Trackingfehler zu suchen. Zuerst muss geklärt werden, auf welcher Ebene die Abweichung entsteht. Wird auf User, Session oder Event geschaut. Gilt dieselbe Identitätslogik. Wird dieselbe Attributionssicht verwendet. Arbeitet der Report mit derselben Verdichtung wie eine Exploration.
Die Zahl beschreibt Reichweite oder Beteiligung aus einer bestimmten Identitätslogik heraus. Sie ist nicht automatisch mit Session- oder Eventzahlen vergleichbar.
Die Zahl beschreibt Interaktionseinheiten. Sie kann steigen oder fallen, ohne dass sich Nutzerzahl oder Key Events im gleichen Verhältnis bewegen.
Die Zahl beschreibt markierte Ereignisse. Je nach Berichtskontext, Attribution und Dimension kann ihre Zuordnung anders aussehen als erwartet.
Typische interne Mismatch-Muster innerhalb von GA4 entstehen an genau diesen Stellen:
| Vergleich | Was sichtbar wird | Warum es auseinanderläuft | Ebene |
|---|---|---|---|
| User Acquisition vs Traffic Acquisition | Unterschiedliche Kanalwerte | First user Logik vs Session source Logik | User vs Session |
| Users vs Active Users | Abweichende Reichweite | Unterschiedliche Definition von Aktivität | Identität / Aktivität |
| Sessions vs Engaged Sessions | Abweichende Leistungswahrnehmung | Engagement filtert Sessionqualität | Session / Qualitätslogik |
| Standard Report vs Explore | Gleiche Frage, andere Zahl | Anderer Berichtskontext, andere Verdichtung | Reportkontext |
| Key Events nach Report | Verschobene Eventwerte | Dimension, Attribution oder Zeitlogik verändert Zuordnung | Event / Attribution |
Genau deshalb ist die erste echte Diagnosefrage nicht: Welche Zahl ist richtig. Sondern: Welcher Report beantwortet hier eigentlich welche Frage.
Warum Explorations den Mismatch sichtbarer machen
Explorations wirken oft wie der präzisere Ort für die Wahrheit. Tatsächlich zeigen sie vor allem, dass Berichtskontext selbst ein Teil des Problems ist.
In vielen Setups sind nicht alle Standardreports verfügbar oder sauber ausgebaut. Dann wirken explorative Datenanalysen wie der logische Ausweg. Das ist auch richtig – aber nur, wenn klar bleibt, dass eine Exploration kein neutraler Endzustand ist.
Eine Freiform-Analyse baut die Frage neu. Dimensionen, Metriken, Zeilen, Visualisierung und Filter werden dort nicht wie im Standardreport vordefiniert mitgeliefert, sondern neu zusammengesetzt. Genau deshalb können Explorations sichtbar andere Zahlen, andere Verteilungen und andere Schwerpunkte zeigen.
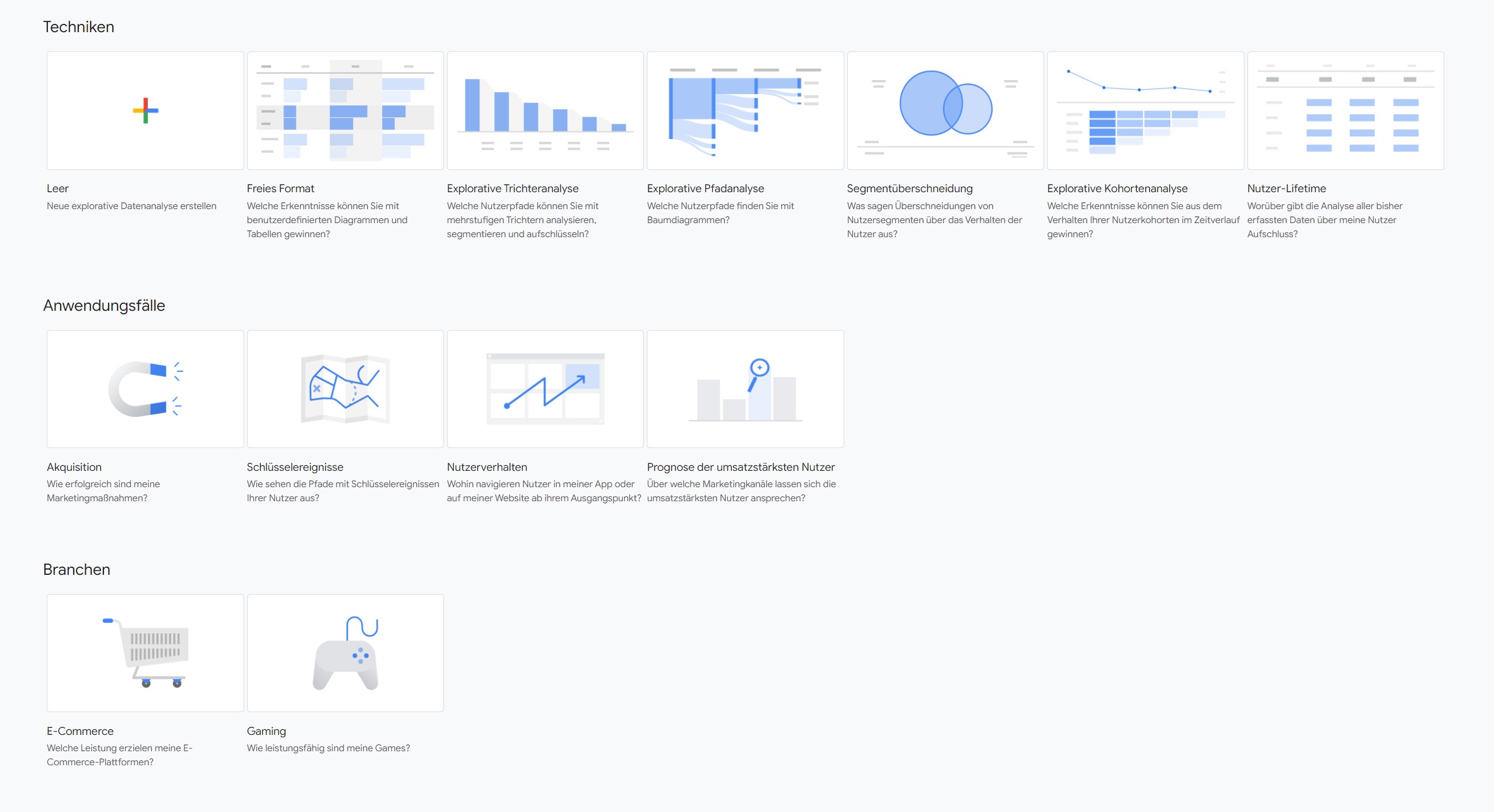
Eine Exploration beantwortet nicht automatisch dieselbe Frage wie ein Standardreport. Sie erzeugt einen eigenen Analysekontext aus Dimensionen, Metriken und Filtern.
Genau das ist im Exploration-Screenshot sichtbar. Die Analyse konzentriert sich auf sitzungsbezogene Kanalgruppen und baut daraus eine eigene Sicht auf den Traffic. Das ist analytisch wertvoll. Aber die Exploration ist nicht deshalb „richtiger“, weil sie freier gebaut wurde. Sie ist nur expliziter in ihrer Konstruktion.
Wenn hier also Werte anders aussehen als im Standardreport, ist das nicht automatisch ein Gegenbeweis gegen den Standardreport. Oft zeigt die Exploration nur klarer, welche Perspektive überhaupt gewählt wurde.
Explorations lösen den Mismatch nicht automatisch auf. Sie machen sichtbarer, dass jede Analyse in GA4 auf einer bestimmten Konstruktionslogik beruht.
Der Mismatch entsteht meist nicht in der Datenerhebung, sondern in der Lesart
Wenn mehrere interne GA4-Berichte widersprüchlich wirken, liegt die Ursache oft nicht in fehlenden Daten. Sie liegt darin, dass Werte aus unterschiedlichen Berichtskontexten wie direkt vergleichbare Messpunkte behandelt werden.
Die Arbeitsannahme lautet deshalb: Der beobachtete Unterschied ist kein Beweis für ein defektes Setup, sondern Ausdruck unterschiedlicher Systemlogiken innerhalb von GA4.
Viele scheinbare Widersprüche in GA4 lösen sich auf, sobald Identität, Aggregation, Attribution und Berichtskontext sauber getrennt werden.
Wie GA4 intern unterschiedliche Realitäten erzeugt
Um interne Data Mismatches zu verstehen, muss GA4 nicht als Dashboard, sondern als mehrschichtiges Berichtssystem gelesen werden. Jede Schicht verdichtet dieselben Rohereignisse auf eine andere Weise. Dadurch entsteht nicht Beliebigkeit, sondern eine kontrollierte Differenz.
Verdichtete Datenräume statt einer einzigen Wahrheit
Ein Report in GA4 zeigt nicht einfach Daten an. Er interpretiert Ereignisse entlang einer bestimmten Logik – zum Beispiel nach User, Session, Event, Attribution, Date Range oder Report Identity. Zwei Reports können deshalb sauber arbeiten und trotzdem verschiedene Zahlen zeigen.
1. Users vs Active Users vs Total Users
Schon auf User-Ebene beginnt die Verschiebung. Wer nur von Users spricht, spricht oft unsauber. Innerhalb von GA4 ist entscheidend, welche konkrete User-Metrik ein Report verwendet. Active Users kann andere Größenordnungen erzeugen als Total Users, weil die Definition von Aktivität eine zusätzliche Schwelle einzieht. Dadurch wirkt Reichweite kleiner oder größer, obwohl nicht dieselben Kriterien gemessen werden.
2. Sessions vs Engaged Sessions
Auch auf Session-Ebene ist Gleichsetzung gefährlich. Sessions zählen Interaktionseinheiten. Engaged Sessions beschreiben eine Teilmenge davon. Wird diese Differenz ignoriert, entsteht schnell die falsche Diagnose, dass Traffic eingebrochen oder Qualität plötzlich explodiert sei. Tatsächlich wurde oft nur von einer Gesamtmenge auf eine qualifizierte Teilmenge gewechselt.
3. Key Events in unterschiedlichen Reports
Key Events werden nicht in jedem Kontext identisch gelesen. Je nach Report, verwendeter Dimension und zugrunde liegender Attributionssicht kann dieselbe markierte Handlung unterschiedlich zugeordnet werden. Dann entsteht nicht nur eine andere Zahl, sondern eine andere Interpretation von Ursache und Wirkung.
Ein guter Gegenpol zu Akquisitions- und Sessionreports ist deshalb der Blick auf Seiten und Bildschirme. Dort wird dieselbe Property nicht als Kanalfluss gelesen, sondern als Inhalts- und Interaktionsraum.
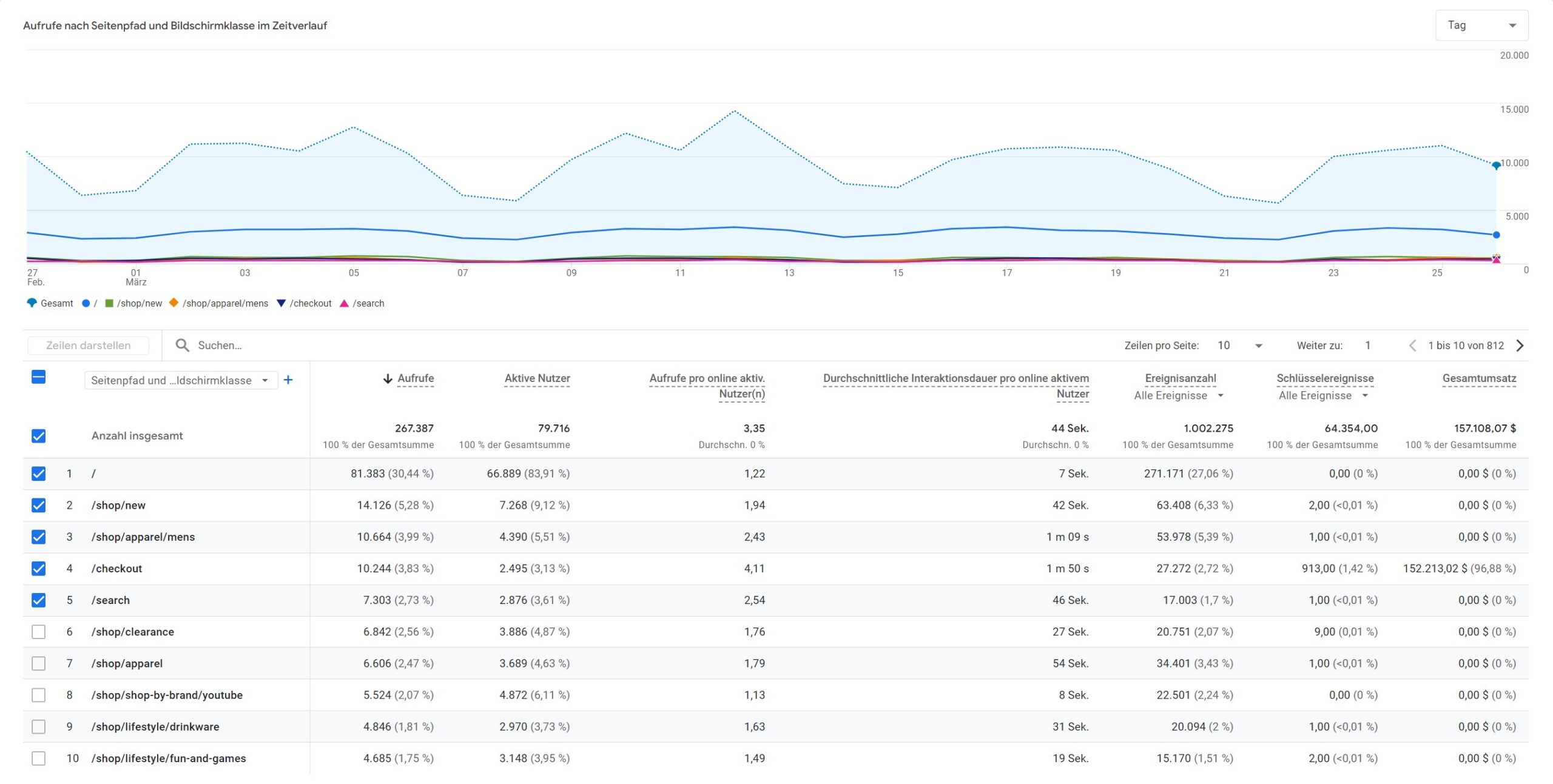
Seiten und Bildschirme verschieben die Perspektive erneut: weg von Quelle und Sitzung, hin zu Inhalt, Aufrufen, aktiven Nutzern und Schlüsselereignissen im Seitenkontext.
Im Screenshot ist diese Logik klar sichtbar. Seitenpfade wie Startseite, Kategorieseiten oder Checkout erscheinen hier nicht als Akquisitionsquellen, sondern als Interaktionsräume. Die Kennzahlen erzählen deshalb auch eine andere Geschichte: Aufrufe, aktive Nutzer, Ereignisanzahl, Schlüsselereignisse und Umsatz hängen nun an Seitenpfaden.
Genau das ist wichtig für die Einordnung. Wenn eine Seite sehr viele Aufrufe, aber relativ wenige Schlüsselereignisse zeigt, ist das keine Aussage über Kanalqualität. Und wenn Checkout im Seitenreport fast den gesamten Umsatz trägt, sagt das nichts darüber aus, welcher Kanal oder welche Sitzung diesen Umsatz ursprünglich vorbereitet hat.
4. Report Identity
Report Identity beeinflusst, wie Nutzer über Geräte und Signale hinweg zusammengeführt werden. Schon dadurch können User-Werte anders aussehen als erwartet. Wer diese Ebene ignoriert, behandelt Identität als fixen Rohwert. In GA4 ist sie aber Teil der Berichtskonstruktion.
5. Attribution Settings und Lookback Windows
Attribution verschiebt nicht das Ereignis selbst, sondern dessen Zuschreibung. Dadurch können Key Events, Kanäle oder Touchpoints in einem Bericht anders wirken als in einem anderen. Lookback Windows verändern zusätzlich, welche Interaktionen überhaupt noch als relevant gelten. Das ist keine kosmetische Einstellung, sondern eine operative Deutung darüber, welchem Kontaktpunkt Wirkung zugesprochen wird.
6. Date Range, Vergleichszeitraum und Berichtskontext
Schon ein leicht veränderter Zeitraum kann in GA4 zu anderen Lesarten führen, wenn Nutzer- oder Attributionslogik im Hintergrund mitwirkt. Wer Standard Reports und Explorations vergleicht, ohne exakt denselben Zeitraum, dieselben Filter und dieselbe Fragelogik zu setzen, produziert oft den Mismatch selbst.
7. Cardinality, Thresholding und sampling-nahe Effekte
Nicht jede Abweichung ist semantisch. Manche Unterschiede entstehen, weil Reports mit hoher Dimensionsvielfalt verdichten, Zeilen zusammenfassen oder Datenschutzschwellen greifen. Gerade in Explorations, in detailreichen Tabellen oder bei granularen Aufschlüsselungen kann der Eindruck entstehen, dass Zahlen ungenau seien. Tatsächlich ist der Bericht dann unter anderen Restriktionen lesbar als ein Standardreport.
GA4 liefert keine einzige absolute Zahl pro Fragestellung, sondern mehrere gültige Antworten – abhängig davon, auf welcher Ebene die Frage gestellt wird.
Wie aus einem Lesefehler eine Fehlsteuerung wird
Der eigentliche Schaden entsteht selten im Reporting selbst. Er entsteht im nächsten Schritt – in der Interpretation. Wenn unterschiedliche Berichtskontexte als direkter Widerspruch gelesen werden, beginnt operative Fehlsteuerung.
Dann werden Kanäle falsch bewertet, weil User-Akquisition mit Session-Leistung vermischt wird. Dann wird Engagement überschätzt oder unterschätzt, weil Sessions gegen Engaged Sessions gestellt werden. Dann wird über vermeintlich verlorene Conversions diskutiert, obwohl nur die Attributionsperspektive gewechselt hat.
Das Problem ist damit nicht mehr nur analytisch. Es wird strategisch. Budgets, Prioritäten und Narrative im Team orientieren sich an Zahlen, die außerhalb ihres Berichtskontexts gelesen wurden.
Nicht der Mismatch selbst steuert falsch, sondern die falsche Annahme, dass alle Zahlen dieselbe Frage beantworten.
Welche Fragen vor jedem Zahlenvergleich gestellt werden müssen
Bevor zwei Werte in GA4 gegeneinander gelesen werden, müssen ein paar Diagnosefragen sauber beantwortet sein. Erst danach ist ein Vergleich überhaupt sinnvoll.
- Beschreiben beide Reports dieselbe Analyseebene – User, Session oder Event?
- Ist dieselbe Identitätslogik aktiv, insbesondere im Hinblick auf Report Identity?
- Wird dieselbe User-Metrik verwendet oder werden verschiedene Nutzerbegriffe vermischt?
- Sind Zeitraum, Vergleichszeitraum und Filter wirklich identisch gesetzt?
- Spielt Attribution eine Rolle und falls ja, mit welchem Modell und welchem Lookback Window?
- Wird ein Standardreport mit einer Exploration verglichen, ohne den Berichtskontext anzugleichen?
- Kann Cardinality, Thresholding oder eine andere Verdichtung die sichtbaren Werte beeinflussen?
- Ist die verwendete Dimension überhaupt passend zur Metrik, die interpretiert werden soll?
Diese Fragen wirken banal. Genau darin liegt das Problem. Viele interne Mismatches in GA4 bleiben bestehen, weil der Vergleich schon auf der Ebene der Fragestellung unsauber aufgebaut wurde.
Die bessere Frage lautet nicht: Welche Zahl stimmt – sondern: Was misst dieser Bericht wirklich
Ein reifes Arbeiten mit GA4 beginnt dort, wo Zahlen nicht mehr isoliert gelesen werden. Die entscheidende analytische Bewegung besteht darin, den Berichtskontext vor den Wert zu stellen.
Ein Standardreport beantwortet eine andere Frage als eine Exploration. Traffic Acquisition beantwortet eine andere Frage als User Acquisition. Eine auf Sessions gelesene Entwicklung ist keine Aussage über Nutzeridentität. Ein Key Event in einem Attributionskontext ist keine rohe Eventzählung.
Sobald diese Trennung sauber gelingt, verschiebt sich die Arbeit mit GA4. Aus vermeintlich widersprüchlichen Zahlen wird kein Chaos mehr, sondern ein System von Perspektiven. Genau dann beginnt Reporting brauchbar zu werden.
GA4 zeigt oft keine falschen Zahlen – sondern unterschiedlich gebaute Wahrheiten
Interner Data Mismatch in GA4 ist häufig kein technischer Defekt, sondern ein Interpretationsproblem. Dieselben Rohereignisse werden in verschiedenen Reports entlang anderer Regeln verdichtet, gefiltert, identifiziert und zugeordnet.
Wer diese Regeln nicht mitliest, hält Berichtskontext für Widerspruch. Wer sie mitliest, erkennt, dass viele Abweichungen nicht nur erklärbar, sondern systemisch korrekt sind.
In GA4 ist nicht jede Zahl universell. Sie ist nur innerhalb des Berichtskontexts korrekt, der sie hervorgebracht hat.
Relevante Data Sources für diese Einordnung
- Reports Snapshot: für den ersten Überblick über zentrale Kennzahlen und deren sichtbare Verdichtung.
- Reports – Acquisition – User acquisition: für First user source, First user default channel group und userbezogene Akquisitionslogik.
- Reports – Acquisition – Traffic acquisition: für Session source, Session default channel group, Sessions und Engaged Sessions.
- Reports – Engagement – Pages and screens: für Seitensicht, Views, Users, Key Events und Umsatz im Seitenkontext.
- Explore – Free Form: für denselben Analysegegenstand in einem anderen Berichtskontext.
- Admin – Reporting identity: für die Identitätslogik hinter User-Zahlen.
- Attribution Settings und Lookback Windows: für Abweichungen in der Zuschreibung von Schlüsselereignissen, sofern im Setup sichtbar.
- Realtime und DebugView: nicht zur Erklärung des Mismatch selbst, aber zur Abgrenzung von tatsächlichen Implementierungsproblemen.